Partial etcd Recovery on Openshift / Kubernetes
For those out there, playing in the land of Kubernetes / Openshift, we know about etcd and how it’s the backend that stores the data for Kubernetes. We also know it’s important and that is why most Kubernetes installation docs will say “install 3 etcd replicas” so that if one fails you are fine.
etcd is also super lightweight, meaning you can back up clusters in a minute with a small snapshot file.
Here is an example of an etcd snapshot size of a cluster of 16 nodes running 662 pods.

About 300Mb for a daily backup and 2.3Gb for 8 days worth of backups is nothing these days. The backups are also very quick. In some clusters we backup 4 times a day because the sizes are so small and the backup/etcd snapshotting is so quick.
So etcd is amazing and quick and light and highly available, what is not to love. Well, there is one small thing that is a bit of a problem for us. When you do an etcd restore it’s all or nothing. These snapshots are designed to restore a cluster that has had a total failure. But I live in the real world, where I do not have clusters with total failures. I work with users. Users who work on large clusters with their own namespaces/projects who end up deleting their own stuff and then asking me to do a restore. Here is a typical conversation.
User: I deleted all my stuff, can you put it back.
Me: Did you make a backup?
User: No, don’t you have backups?
Me: Yes, Thank God for Me.
User: Ok, just restore my stuff!
Me: It doesn’t work that way, I have to restore the entire cluster which will affect everybody else.
User: Ok, let me know when you have restored my stuff.
Me: No, it doesn’t work that way!
User: I’m off to get a coffee, bye.
The Truth Please! What actually happened?
Ok, you got me. In this case I was the user. I deleted some pretty important stuff in a pretty important namespace/project which caused some pretty nasty things to happen.

The cluster in question is a 49 Node cluster with 205 projects running 1715 pods. We have lots of teams on this cluster, making changes all the time, so it’s very active and runs business critical applications. I know everybody thinks their app is important and business critical, but these are actually important because they make money (businesses loves themselves some money).
I am not going to go into the details of why I did what I did, or what I was thinking, this is not important and embarrassing. What I want to do is celebrate the important lesson I learnt, which is when you break something, find someone smarter than you and can get them to save your arse. At least that way you can also blame the other person.
Seriously though, I am happy this happened because it taught me something new about etcd & Kubernetes / Openshift that I want to share with everybody because I am certain someone else out there is going to face a similar situation.
So what happened? Something like this…
$ oc delete secrets --all -n openshift-infraThere are secrets in the openshift-infra projects? Yeah…. and there are kinda of a lot…..
$ oc get secrets -n openshift-infra | wc -l
168I deleted 168 secrets that are pretty important… But let’s not dwell on this for now, let’s move forward!
The situation we (remember I have a buddy now ) found ourselves in, is that we need to restore a bunch of secrets from a specific namespace without impacting any of the users in the cluster. And this is how we ended up saving ourselves from ourselves without anybody even noticing.
Get On With it!
The goal was to get only the information I wanted, out of etcd, into a usable YAML format, where I could simply add it back to the cluster.
I am now gonna show you how we recovered from this, which is a procedure you can use when you want to only restore a specific section of your Kubernetes cluster
Step 1: Get the backups!
I downloaded the last nightly backup to my local machine
scp master01-from-important-client:/var/lib/etcd/snapshot.db /tmp/
snapshot.db 100% 166MB 3.6MB/s 00:45Step 2: Install etcd locally
I run Fedora. I also didn’t care that the etcd version were not identical. This will make sense later.
$ dnf install etcd
Step 3: Restore the snapshot to my local PC
$ etcdctl snapshot restore /tmp/snapshot.db 
It should have restored the name as “default”.
You can verify this by looking at the default etcd location
$ ls -la /var/lib/etcd/
total 4
drwxr-xr-x. 3 etcd etcd 26 Jun 11 13:41 .
drwxr-xr-x. 70 root root 4096 Jun 11 11:08 ..
drwx------. 3 etcd etcd 20 Jun 11 13:41 default.etcdYou should see “default.etcd” If you see a different name, then when you start up etcd change “ — name default” to whatever you see.
Step 4: Start up etcd
This command will start up the etcd named “default”
$ etcd --name default --listen-client-urls http://localhost:2379 --advertise-client-urls http://localhost:2379 --listen-peer-urls http://localhost:2380
This will run etcd in the foreground. Leave it there and start up another terminal session
Step 5: Confirm snapshot actually worked
Now I have all the data from my client running on my laptop, thanks to the simple snapshot capability of etcd
Let’s see what’s inside.
$ etcdctl get / --prefix --keys-onlyYou should see lots and lots of keys
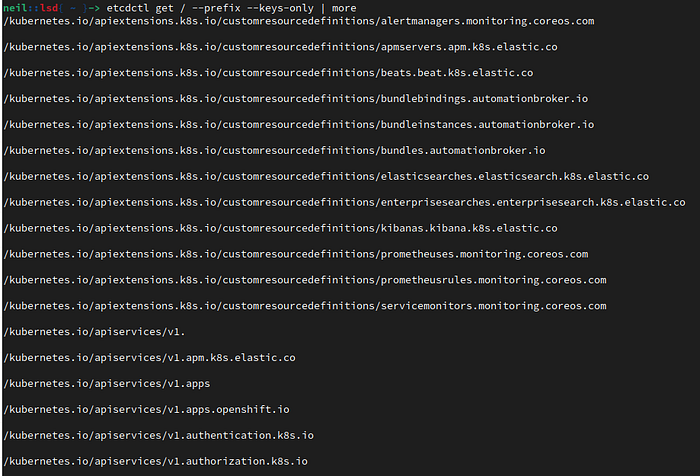
This is how many I see
$ etcdctl get / --prefix --keys-only | wc -l
12932I am interested in is everything in the namespace/project “openshift-infra”
Let’s see if there is data for that namespace/project
$ etcdctl get / --prefix --keys-only | grep openshift-infra/kubernetes.io/controllers/openshift-infra/hawkular-cassandra-1
/kubernetes.io/controllers/openshift-infra/hawkular-metrics
/kubernetes.io/controllers/openshift-infra/heapster
/kubernetes.io/jobs/openshift-infra/hawkular-metrics-schema
/kubernetes.io/namespaces/openshift-infra
/kubernetes.io/pods/openshift-infra/hawkular-cassandra-1-7ftn8
/kubernetes.io/pods/openshift-infra/hawkular-metrics-5sckh
/kubernetes.io/pods/openshift-infra/heapster-d9gwb
/kubernetes.io/rolebindings/openshift-infra/admin
/kubernetes.io/rolebindings/openshift-infra/edit
/kubernetes.io/rolebindings/openshift-infra/hawkular-view
/kubernetes.io/rolebindings/openshift-infra/system:deployer
/kubernetes.io/rolebindings/openshift-infra/system:deployers
/kubernetes.io/rolebindings/openshift-infra/system:image-builder
/kubernetes.io/rolebindings/openshift-infra/system:image-builders
/kubernetes.io/rolebindings/openshift-infra/system:image-puller
/kubernetes.io/rolebindings/openshift-infra/system:image-pullers
/kubernetes.io/secrets/openshift-infra/build-controller-token-hk9gz
/kubernetes.io/secrets/openshift-infra/build-controller-token-xv2gt
/kubernetes.io/secrets/openshift-infra/builder-dockercfg-qtt2c
/kubernetes.io/secrets/openshift-infra/builder-token-dx9rb
/kubernetes.io/secrets/openshift-infra/builder-token-pvss7
/kubernetes.io/secrets/openshift-infra/cassandra-dockercfg-hqcgd
/kubernetes.io/secrets/openshift-infra/cassandra-dockercfg-jcjm9
/kubernetes.io/secrets/openshift-infra/cassandra-dockercfg-wlhcf
/kubernetes.io/secrets/openshift-infra/cassandra-token-27m8v
/kubernetes.io/secrets/openshift-infra/cassandra-token-khzqx
/kubernetes.io/secrets/openshift-infra/cassandra-token-qq4lh
/kubernetes.io/secrets/openshift-infra/cassandra-token-v4zg7
/kubernetes.io/secrets/openshift-infra/cassandra-token-vt4kn
/kubernetes.io/secrets/openshift-infra/cassandra-token-wgczj
...
There we go baby! Some sweet sweet data.
Step 6: Get the exact data we want
Now that we can see our data, I want to only extract exactly what we need. In my case it is the secrets in the namespace/project “openshift-infra”. You might need persistent volumes, or config maps, it doesn’t matter the resource as the procedure is the exact same.
In this example I am going to pick on one secret to demonstrate how we do this: the default secret
The default secret is part of every single namespace that gets created in Kubernetes.
$ etcdctl get / --prefix --keys-only | grep openshift-infra | grep secret | grep default/kubernetes.io/secrets/openshift-infra/default-dockercfg-5w5dq
/kubernetes.io/secrets/openshift-infra/default-rolebindings-controller-dockercfg-xm6k8
/kubernetes.io/secrets/openshift-infra/default-rolebindings-controller-token-9lpq9
/kubernetes.io/secrets/openshift-infra/default-rolebindings-controller-token-pn2n4
/kubernetes.io/secrets/openshift-infra/default-token-5np58
/kubernetes.io/secrets/openshift-infra/default-token-7c7tz
We are going to inspect: /kubernetes.io/secrets/openshift-infra/default-token-7c7tz
$ etcdctl get /kubernetes.io/secrets/openshift-infra/default-token-7c7tzYou should see something like this (this is from a test cluster, so these certificates you see are useless, in case you are concerned for me)

Alright then! We can see data!! But… I wish it was that simple…
See those pesky Unicode symbolism…Yeah, they are a problem.
What we need is that data, without the stupid question marks, and in a YAML format.

Step 7: Why Hello Auger
I say this all the time, I am so happy there are smart generous people in this world, that have created such magnificent tools like Auger
Auger will allow us to decode the data in a format we can use, check it out!
$ etcdctl get /kubernetes.io/secrets/openshift-infra/default-token-7c7tz --print-value-only | auger decodeAnd we get the beautiful, usable, YAML that we love so much.

Step 8: Rinse and Repeat
Now I can use a simple for loop to get my lovely data
$ mkdir -p /tmp/yaml ; cd /tmp/yaml
$ etcdctl get / --prefix --keys-only | grep openshift-infra | grep "/secrets/" > secrets.listThe contents of that file
$ cat secrets.list/kubernetes.io/secrets/openshift-infra/cassandra-token-27m8v
/kubernetes.io/secrets/openshift-infra/cassandra-token-khzqx
/kubernetes.io/secrets/openshift-infra/cassandra-token-qq4lh
/kubernetes.io/secrets/openshift-infra/cassandra-token-v4zg7
/kubernetes.io/secrets/openshift-infra/cassandra-token-vt4kn
/kubernetes.io/secrets/openshift-infra/cassandra-token-wgczj
/kubernetes.io/secrets/openshift-infra/default-dockercfg-5w5dq
/kubernetes.io/secrets/openshift-infra/default-token-5np58
/kubernetes.io/secrets/openshift-infra/default-token-7c7tz
/kubernetes.io/secrets/openshift-infra/deployer-dockercfg-tdjnz
/kubernetes.io/secrets/openshift-infra/deployer-token-6jc8c
/kubernetes.io/secrets/openshift-infra/deployer-token-8hp6c
/kubernetes.io/secrets/openshift-infra/deployment-trigger-
...
Then we loop through that and get all our secrets
$ for x in $(cat secrets.list) ; do secret_name=$(echo "$x" | awk -F\/ '{print $5}') ; echo $secret_name ; etcdctl get $x --print-value-only | auger decode > $secret_name.secret.yaml ; doneAnd now we have all our secrets for “openshift-infra”
$ ls -1
build-config-change-controller-dockercfg-9khqd.secret.yaml
build-config-change-controller-token-2csmb.secret.yaml
build-config-change-controller-token-h2wxd.secret.yaml
build-controller-dockercfg-9chcf.secret.yaml
build-controller-token-hk9gz.secret.yaml
build-controller-token-xv2gt.secret.yaml
builder-dockercfg-qtt2c.secret.yaml
builder-token-dx9rb.secret.yaml
builder-token-pvss7.secret.yaml
cassandra-dockercfg-hqcgd.secret.yaml
cassandra-dockercfg-jcjm9.secret.yaml
cassandra-dockercfg-wlhcf.secret.yaml
...Check it out! We have glorious data!

Step 9: Import
I suppose it obvious now that we have the data, we simply apply it
$ for x in $(ls -1 *.yaml ) ; do oc apply -f $x ; doneStep 10: Openshift v3 Extra Steps
You might be asking why were any of these secrets important in “openshift-infra”. How we discovered they were important was when no new builds were working or new deployment configs were rolling out.
For example these commands where executing, but nothing was actually happening
$ oc rollout latest deploymentconfig/libretransate
$ oc start-build -n multisite-routing-prod multisite-routingAfter reading through 1000s of logs and determining it was the secrets we removed, we had to do an additional step to revive the cluster, and that was to restart the controllers and api on all the masters
So for you Openshift v3 people out there, log into all your masters and run the following command to wake up the cluster
$ /usr/local/bin/master-restart api
$ /usr/local/bin/master-restart controllersClosing Thoughts
I hope this helps someone out there that might have a similar situation and that is why I take the time out to write these articles. I would rather be installing a better solution to these types of problems, but I don’t want people to panic and get grey hairs when there is always hope.

The correct solution to this problem would have a better backup tool than relying solely on etcd. And a better backup tool I can recommend is Velero. We will start implementing it at LSD on all our clients that use LSDcontainer, to help us in times of crisis.

And of course a huge thank you to everybody that helped build Auger. Check it out at: https://github.com/jpbetz/auger if you haven’t already clicked on any of the hyperlinks I posted about it. Auger really saved my butt and hopefully can save other butts out there.
